“Usability is an approach to product development that incorporates direct user feedback throughout the development cycle in order to reduce costs and create products and tools that meet user needs.” Usability Professionals’ Association (UPA)
5 Key Quality Components of Usability
Usability is defined by five quality components:
Learnability: How easy is it for users to accomplish basic tasks the first time they encounter the design?
Efficiency: Once users have learned the design, how quickly can they perform tasks?
Memorability: When users return to the design after a period of not using it, how easily can they reestablish proficiency?
Errors: How many errors do users make, how severe are these errors, and how easily can they recover from the errors?
Satisfaction: How pleasant is it to use the design?
There are many other important quality attributes. A key one is utility, which refers to the design’s functionality: Does it do what users need? Usability and utility are equally important: It matters little that something is easy if it’s not what you want. It’s also no good if the system can hypothetically do what you want, but you can’t make it happen because the user interface is too difficult. To study a design’s utility, you can use the same user research methods that improve usability.
Usability is a critical element of user experience. While usability relates to the ease of use of a product, the user experience reflects the overall satisfaction of the user while using the product. The least the user thinks about what he is doing, the better the experience.
Next day 4pm to 6pm we got Business Test 2. The topic covered all aspect of marketing, production, accounting & finance, and Human Resource Management. Whole topics covered something like magic, so much to know, but actually it is very simple, if you know the key.
So I study and study, study till 9pm. In between the time I had slept. Actually I had decided to wash clothes at 4pm, but I not. While I had set the alarm on my handphone but I not take it seriously. I just continued to sleep and sleep.
So until one hours ago, I feel very boring by continuing study the Business, so I proceed to learn something about UCenter.
I want to investigate what beauty behind UCenter, how it works, how it fulfill the SSO (Single Sign On) mechanisms. I learnt from some articles online I knew that a little bit knowledge about UCenter. Suddenly, I also seen one called Loong SSO, it proposed other mechanisms to fulfill SSO, it utilized C to install that program in Linux server. The specialty of that is that provide high speed caching system, because using C. But if not install that particular thing, the techniques that fulfilled in UCenter is enough. However, in theoretically, in comparison between these two, UCenter will has lower efficiency since when your application is up more over than 10, you will experienced low speed when you try to login one of the applications. It is because in the realization of UCenter, when you try to login, it will use something seem like AJAX, but called it AJAJ more suitable, use for each to iterate all applications and sent the login request and P3P to fulfill single sign on.
Yes, since I haven’t very understand the actually mechanisms behind that, but maybe got a very little knowledge about that.
Since that is a plan for us to explore the new UCenter-liked mechanisms to achieve a high SNS world. How to do that? Currently in this situation UCenter which acts liked a Window system can install as many as possible of software, or called application, like forum, ecshop, uchome and such kind of thing. However somehow the current mechanism only support one UCHOME, that meant one SNS platform which utilized the UCenter. How about if we combine the different organization, different forum, ecshop, specialized in uchome, but not strongly affected them, to link them to our new UCenter mechanisms, for example, we called, XCenter. In XCenter, the application may can be the common one, for example, forum, ecshop, and also the UCHOME, and also one thing, UCenter. Every UCenter can link to our XCenter. But I want to say, if the UCenter login mechanism continued using in the XCenter, yes, it is very possible the efficiency and the speed will lost. So, actually I still be in thinking how to solve this problem. I had doubt that why all login cookies domain must be achieved in order to fulfill single sign on. Is it any other possible road to achieve, but not strongly affected them and not affected the efficiency of the system? How about using Unified Cookie Domain secques to fulfill it. That meant that any member related is only in XCenter. Besides achieve that, one thing must be known that, the database server will be suffered. How about the way of using C to achieve high quality of caching. But how instead of using C we can also achieve high quality of caching? How to solve this problem? It seem that not keeping speaking to the air here but not going to solve that problem. But however it giving the thinking road how to leak into the problem and find the solution. Anything is under brainstorming.
Besides learning UCenter, I also experienced that I need to learn more about RESTful style, how about the POST,GET,DELETE,PUT. The more popular open API such as Google API and Yahoo API is the most standard conformance RESTful style. I want to know about is it UCenter is a kind of RESTful style? I have doubted because I seen its code definition is nearly same… Sure, I need to make a deeper understanding to solve my doubt.
Last paragraph talked about my current study. Since this week I think is the last week for this semester for us to rush our projects. Since this week I got three presentation, and then need t submit three projects or group assignments. So it is very stressful but after that it will be some time not very stress. I meant that because later will be the final exam, we only wait for final exam, and after that that is the time I go back to our hometown.
As a Google user, you’re familiar with the speed and accuracy of a Google search. How exactly does Google manage to find the right results for every query as quickly as it does? The heart of Google’s search technology is PigeonRank™, a system for ranking web pages developed by Google founders Larry Page and Sergey Brin at Stanford University.
Building upon the breakthrough work of B. F. Skinner, Page and Brin reasoned that low cost pigeon clusters (PCs) could be used to compute the relative value of web pages faster than human editors or machine-based algorithms. And while Google has dozens of engineers working to improve every aspect of our service on a daily basis, PigeonRank continues to provide the basis for all of our web search tools.
Why Google’s patented PigeonRank™ works so well
PigeonRank’s success relies primarily on the superior trainability of the domestic pigeon (Columba livia) and its unique capacity to recognize objects regardless of spatial orientation. The common gray pigeon can easily distinguish among items displaying only the minutest differences, an ability that enables it to select relevant web sites from among thousands of similar pages.
By collecting flocks of pigeons in dense clusters, Google is able to process search queries at speeds superior to traditional search engines, which typically rely on birds of prey, brooding hens or slow-moving waterfowl to do their relevance rankings.
When a search query is submitted to Google, it is routed to a data coop where monitors flash result pages at blazing speeds. When a relevant result is observed by one of the pigeons in the cluster, it strikes a rubber-coated steel bar with its beak, which assigns the page a PigeonRank value of one. For each peck, the PigeonRank increases. Those pages receiving the most pecks, are returned at the top of the user’s results page with the other results displayed in pecking order.
Integrity
Google’s pigeon-driven methods make tampering with our results extremely difficult. While some unscrupulous websites have tried to boost their ranking by including images on their pages of bread crumbs, bird seed and parrots posing seductively in resplendent plumage, Google’s PigeonRank technology cannot be deceived by these techniques. A Google search is an easy, honest and objective way to find high-quality websites with information relevant to your search.
Data
PigeonRank Frequently Asked Questions
How was PigeonRank developed?
The ease of training pigeons was documented early in the annals of science and fully explored by noted psychologist B.F. Skinner, who demonstrated that with only minor incentives, pigeons could be trained to execute complex tasks such as playing ping pong, piloting bombs or revising the Abatements, Credits and Refunds section of the national tax code.
Brin and Page were the first to recognize that this adaptability could be harnessed through massively parallel pecking to solve complex problems, such as ordering large datasets or ordering pizza for large groups of engineers. Page and Brin experimented with numerous avian motivators before settling on a combination of linseed and flax (lin/ax) that not only offered superior performance, but could be gathered at no cost from nearby open space preserves. This open space lin/ax powers Google’s operations to this day, and a visit to the data coop reveals pigeons happily pecking away at lin/ax kernels and seeds.
What are the challenges of operating so many pigeon clusters (PCs)?
Pigeons naturally operate in dense populations, as anyone holding a pack of peanuts in an urban plaza is aware. This compactability enables Google to pack enormous numbers of processors into small spaces, with rack after rack stacked up in our data coops. While this is optimal from the standpoint of space conservation and pigeon contentment, it does create issues during molting season, when large fans must be brought in to blow feathers out of the data coop. Removal of other pigeon byproducts was a greater challenge, until Page and Brin developed groundbreaking technology for converting poop to pixels, the tiny dots that make up a monitor’s display. The clean white background of Google’s home page is powered by this renewable process.
Aren’t pigeons really stupid? How do they do this?
While no pigeon has actually been confirmed for a seat on the Supreme Court, pigeons are surprisingly adept at making instant judgments when confronted with difficult choices. This makes them suitable for any job requiring accurate and authoritative decision-making under pressure. Among the positions in which pigeons have served capably are replacement air traffic controllers, butterfly ballot counters and pro football referees during the "no-instant replay" years.
Where does Google get its pigeons? Some special breeding lab?
Google uses only low-cost, off-the-street pigeons for its clusters. Gathered from city parks and plazas by Google’s pack of more than 50 Phds (Pigeon-harvesting dogs), the pigeons are given a quick orientation on web site relevance and assigned to an appropriate data coop.
Isn’t it cruel to keep pigeons penned up in tiny data coops?
Google exceeds all international standards for the ethical treatment of its pigeon personnel. Not only are they given free range of the coop and its window ledges, special break rooms have been set up for their convenience. These rooms are stocked with an assortment of delectable seeds and grains and feature the finest in European statuary for roosting.
What’s the future of pigeon computing?
Google continues to explore new applications for PigeonRank and affiliated technologies. One of the most promising projects in development involves harnessing millions of pigeons worldwide to work on complex scientific challenges. For the latest developments on Google’s distributed cooing initiative, please consider signing up for our Google Friends newsletter.
Note: This page was posted for April Fool’s Day – 2002.
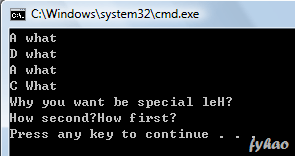
Let see I just built some strange structure of method extend… I want to see how much it can go with different level, where go in where go out. The entrance…
class A { public void what() { System.out.println("A what"); }
public void how() { System.out.println("How first?"); } }
class B extends A { public void how() { System.out.print("How second?"); super.how(); } }
class C extends B { public void what() { System.out.println("C What"); }
public void why() { System.out.println("Why you want be special leH?"); } }
class D extends C { public void what() { System.out.println("D what"); } }
class E extends D { public void what() { System.out.println("E what"); } }
class ExtendMethod { public static void main(String args[]) { A a = new A(); a.what();
C c = new D(); c.what();
A someElse = new B(); someElse.what();
B someThingElse = new C(); someThingElse.what();
B someSpecial = new C(); //someSpecial.why();
D someThingSpecial = new E(); someThingSpecial.why();
Final variables declared inside class, it can be divided into final variable, or static final variable.
These two types have two different initialization method.
For final variable, the first type, we should declare it in constructor, or initializer block.
For static final variable, the second type, we should declare it in static initializer block.
These two methods unless you initialized them when you declare. I mean final int a = 3; you directly assign a number 3 to it.
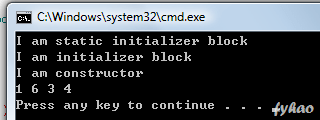
Now, I am playing around with initialization of final variables, as the below is my coding, you all can refer it…
public class FinalStuff { final int a;
static final int d;
// use static initializer block to initialize static final int static { c = 3; d = 4; System.out.println("I am static initializer block"); } static final int c;
{ a = 1 + this.b; b = 2 + this.d; System.out.println("I am initializer block"); } final int b; // use initializer block OR FinalStuff constructor to initialize final int public FinalStuff() { //a = 1; //b = 2; System.out.println("I am constructor"); }
public static void main(String args[]) { FinalStuff f = new FinalStuff(); System.out.println(f.a + " " + f.b + " " + f.c + " " + f.d); } }
Enum is a new Java SE 5 features. It seem likes able to declare a new type, with limited specified value. Below is the demonstration of Enum.
enum Car { TOYOTA (30000,1000,"BIG"), CAMRY (100000,200,"BIG") { public int totalPrice() { return price * unit + 1500; } }, PROTON (10000,5000,"MEDIUM");
final int price; final int unit; final String size;
Car(int price, int unit, String size) { this.price = price; this.unit = unit; this.size = size; }
public int getPrice() { return price; } public int getUnit() { return unit; } public String getSize() { return size; }
public class EnumPlay { public static void main(String args[]) { Car c1 = Car.TOYOTA; Car c2 = Car.CAMRY; Car c3 = Car.PROTON;
for(Car c : Car.values()) { System.out.println(c.name()+ "\n" + c + "\nTotal: " + c.totalPrice() + "\n"); }
System.out.println("Split it up:"); System.out.println(c1.name() + " has " + c1.getUnit() + " cars. Each price costs " + c1.getPrice() + ". But somehow it is " + c1.getSize().toLowerCase()); System.out.println(c2.name() + " has " + c2.getUnit() + " cars. Each price costs " + c2.getPrice() + ". But somehow it is " + c2.getSize().toLowerCase()); System.out.println(c3.name() + " has " + c3.getUnit() + " cars. Each price costs " + c3.getPrice() + ". But somehow it is " + c3.getSize().toLowerCase()); } }
Note that, System.out.printf and System.out.format is exactly the same, the Java engineer come out with System.out.printf may be want to make C Programmer happy.
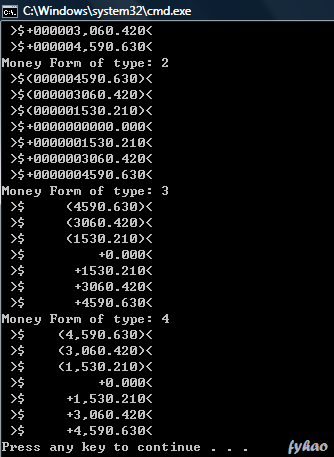
Now, I am going to use this System.out.printf to format my money, in account book, for example, there are different type of formatting. I now tied up with my code, and the output let you to see what happen in this.
import java.util.*; import java.text.*;
class MoneyForm { private double amount; private int type; public MoneyForm(double amount, int type) { this.amount = amount; this.type = type; }
public void generateForm() { switch(type) { case 0: System.out.printf(" >$%1$-+,(15.3f< ", amount); break; case 1: System.out.printf(" >$%1$0+,(15.3f< ", amount); break; case 2: System.out.printf(" >$%1$0+(15.3f< ", amount); break; case 3: System.out.printf(" >$%1$+(15.3f< ", amount); break; case 4: System.out.printf(" >$%1$+,(15.3f< ", amount); break; }
System.out.println(); } }
class Money { public static void main(String args[]) { for(int i=0; i<5; i++) printMoney(i); }
public static void printMoney(int type) { System.out.println("Money Form of type: " + type); for(int i=-3; i<=3; i++) new MoneyForm(i * 1530.21, type).generateForm();
It will return "TRUE". Why? Why show two different results, one return false the other return true. But how come, it is same concept!!!
Confusing?
The answer is, in order to save memory, two instances of the following wrapper objects will always be == when their primitive value are the same.
Boolean
Byte
Character from \u0000 to \u007f (7f is 127 in decimal)
Short and Integer from -128 to 127.
Yes, I know it, in order to save memory, so it become like that. So why first time I see it I will get confused, is it the book talk wrong thing? Not! I try in my machine, it showed the same result.
If I not see this, if the Sun Exam come out this question, I definite will… So I need to be very very careful about this. Since Java 5 the creator of Java is giving programmer more convenient way to construct code, so it may be some things not following logic, so as a testtaker we need to be very careful about this.
This is the demonstration on how to use java.util.Comparable and java.util.Comparator to sort data. In this example, I would using some example of student data, to sort it using both ways.
Comparable is an interface under java.util, the class of the student data must implements it, in order using Collections.sort() to sort it. The programmer need to implements the compareTo() method in order to achieve it.
Comparator is another interface under java.util, it provide more flexibility in sorting the data in many ways. With using Comparator, the programmer is required to make another class which implements Comparator but no implements on class of student data. The benefits are we need not to modify the class of data being sorted, and also we can create as more as possible the Comparator class, provide many sorting method. Lastly, the programmer need to implements the compare() method in order to achieve it.
Here I using the Comparable to sort the Student Data. Below is the code and the output.
import java.util.*;
// Demonstrate using Comparable to sort the student data based on ID, Name, Age
class Student implements Comparable<Student> { private int ID; private String name; private int age;
public Student(int i, String s, int a) { ID = i; name = s; age = a; }
public int getID() {return ID;} public String getName() {return name;} public int getAge() {return age;}
public int compareTo(Student stu) { // sort based on ID return this.ID – stu.ID; }
public String toString() { return ID + "\t" + name + "\t" + age; } }
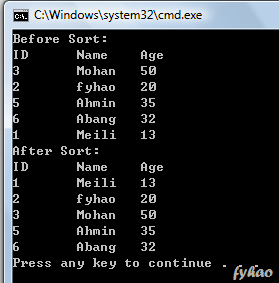
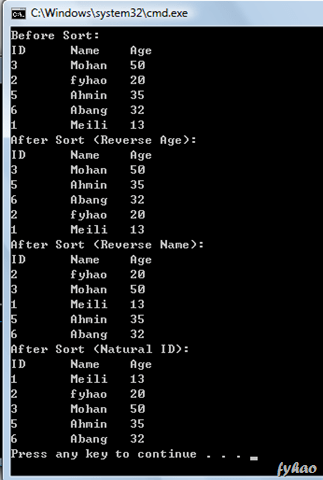
public class StudentData { public static void main(String args[]) { List<Student> list = new ArrayList<Student>(); list.add(new Student(3,"Mohan",50)); list.add(new Student(2,"fyhao",20)); list.add(new Student(5,"Ahmin",35)); list.add(new Student(6,"Abang",32)); list.add(new Student(1,"Meili",13));
System.out.println("Before Sort:\nID\tName\tAge"); for(Student stu : list) { System.out.println(stu); }
Where below is the implementation of the code using Comparator to sort it. I demonstrated it using three different sorting method, you all can check it out from below the code and the output.
import java.util.*;
// Demonstrate using Comparator to sort the student data based on ID, Name, Age
class Student { private int ID; private String name; private int age;
public Student(int i, String s, int a) { ID = i; name = s; age = a; }
public int getID() {return ID;} public String getName() {return name;} public int getAge() {return age;}
public String toString() { return ID + "\t" + name + "\t" + age; } }
class reverseAge implements Comparator<Student> { public int compare(Student s1, Student s2) { return s2.getAge() – s1.getAge(); } }
class reverseAlphabetical implements Comparator<Student> { public int compare(Student s1, Student s2) { return s2.getName().compareTo(s1.getName()); } }
class naturalID implements Comparator<Student> { public int compare(Student s1, Student s2) { return s1.getID() – s2.getID(); } }
public class StudentData { public static void main(String args[]) { List<Student> list = new ArrayList<Student>(); list.add(new Student(3,"Mohan",50)); list.add(new Student(2,"fyhao",20)); list.add(new Student(5,"Ahmin",35)); list.add(new Student(6,"Abang",32)); list.add(new Student(1,"Meili",13));
System.out.println("Before Sort:\nID\tName\tAge"); for(Student stu : list) { System.out.println(stu); }
I currently doing some sample or experiments about generic collection, a new thing added in Java SE 5. It is very interesting but a bit complex, so I need to deep study about it.
Here is my code and the interface shown.
import java.util.*;
class Some { public <T> T getCode(T n) { return n; } }
abstract class Animal<E> { abstract void eat(E x); }
class Fish<E extends Animal> extends Animal<E> { public void eat(E x) { System.out.println("Fish: " + x); } }
class Cat<E extends Fish> extends Animal<E> { public void eat(E x) { System.out.println("Cat: " + x); } }
class Dog<E extends Animal> extends Animal<E> { public void eat(E x) { System.out.println("Dog: " + x); } }
class MyEatList { public void addFish(List<? super Fish> list) { list.add(new Fish()); }
public void addDog(List<? super Dog> list) { list.add(new Dog()); }
}
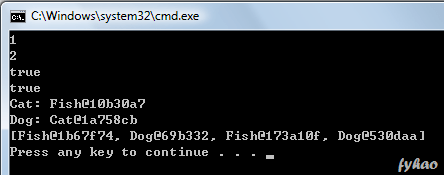
class GenericClass { public static void main(String args[]) { Some s = new Some(); System.out.println(s.getCode(1)); System.out.println(s.getCode("2")); System.out.println((s.getCode(1) instanceof Integer)); System.out.println(s.getCode("2") instanceof String);
Cat<Fish> c = new Cat<Fish>(); c.eat(new Fish());
Dog<Cat> d = new Dog<Cat>(); d.eat(new Cat());
List<Animal> eatList = new ArrayList<Animal>(); MyEatList menu = new MyEatList(); menu.addFish(eatList); menu.addDog(eatList); menu.addFish(eatList); menu.addDog(eatList); System.out.println(eatList); } }

 When a search query is submitted to Google, it is routed to a data coop where monitors flash result pages at blazing speeds. When a relevant result is observed by one of the pigeons in the cluster, it strikes a rubber-coated steel bar with its beak, which assigns the page a PigeonRank value of one. For each peck, the PigeonRank increases. Those pages receiving the most pecks, are returned at the top of the user’s results page with the other results displayed in pecking order.
When a search query is submitted to Google, it is routed to a data coop where monitors flash result pages at blazing speeds. When a relevant result is observed by one of the pigeons in the cluster, it strikes a rubber-coated steel bar with its beak, which assigns the page a PigeonRank value of one. For each peck, the PigeonRank increases. Those pages receiving the most pecks, are returned at the top of the user’s results page with the other results displayed in pecking order.